Python 中的多进程和多线程:你应该知道的知识
编程这么多年,我发现没有哪个语言会像 Python 这样,为了多进程和多线程编程,出现这么多争论。为了弥补 Python 的性能问题,出了这么多的框架和类库,比如 greenlet 和 gevent。 甚至一大堆人去喷 GIL ( Global Interpreter Lock,全局解释锁 )
当然了,本章节我们并不讨论这些,仅仅是讨论 Python 的多进程编程和多线程编程,而且仅限于使用层面
从某些方面说,如果你不想深入了解多进程和多线程那些本质的东西,那么这篇文章就是以一直等待的
而对于什么时候选择多进程 multiprocessing ,什么时候应该选择多线程 threading,也似乎有了一个明确的答案,那就是
如果程序是一个网络应用程序,也就是 IO 密集型的,使用多线程 threading ,如果是 CPU 密集型的程序,可以使用多进程 multiprocessing
我们写了这篇文章,因为当我们寻找多线程和多进程之间的差异时,找到的信息都是毫无理由的难以理解。那些信息走得太深入,没有真正触及有助于我们决定使用什么以及如何实施的信息
什么是线程?为什么你想要它 ?
从本质上讲,Python 是一种线性语言,但是当你需要更多处理能力时,threading 模块就会派上用场。虽然Python 中的线程不能用于并行 CPU 计算,但它非常适合网络抓取等 I/O 操作,因为处理器一般处于空闲状态等待数据
线程是改变游戏规则的,因为许多与网络/数据 I/O 相关的脚本花费大部分时间等待来自远程源的数据。因为多个下载之间并没有任何相互关系 ( 即,单独的从网站抓取 ),处理器可以并行地从不同的数据源下载并在最后组合结果
而对于 CPU 密集型进程,使用 threading 模块几乎没有任何好处
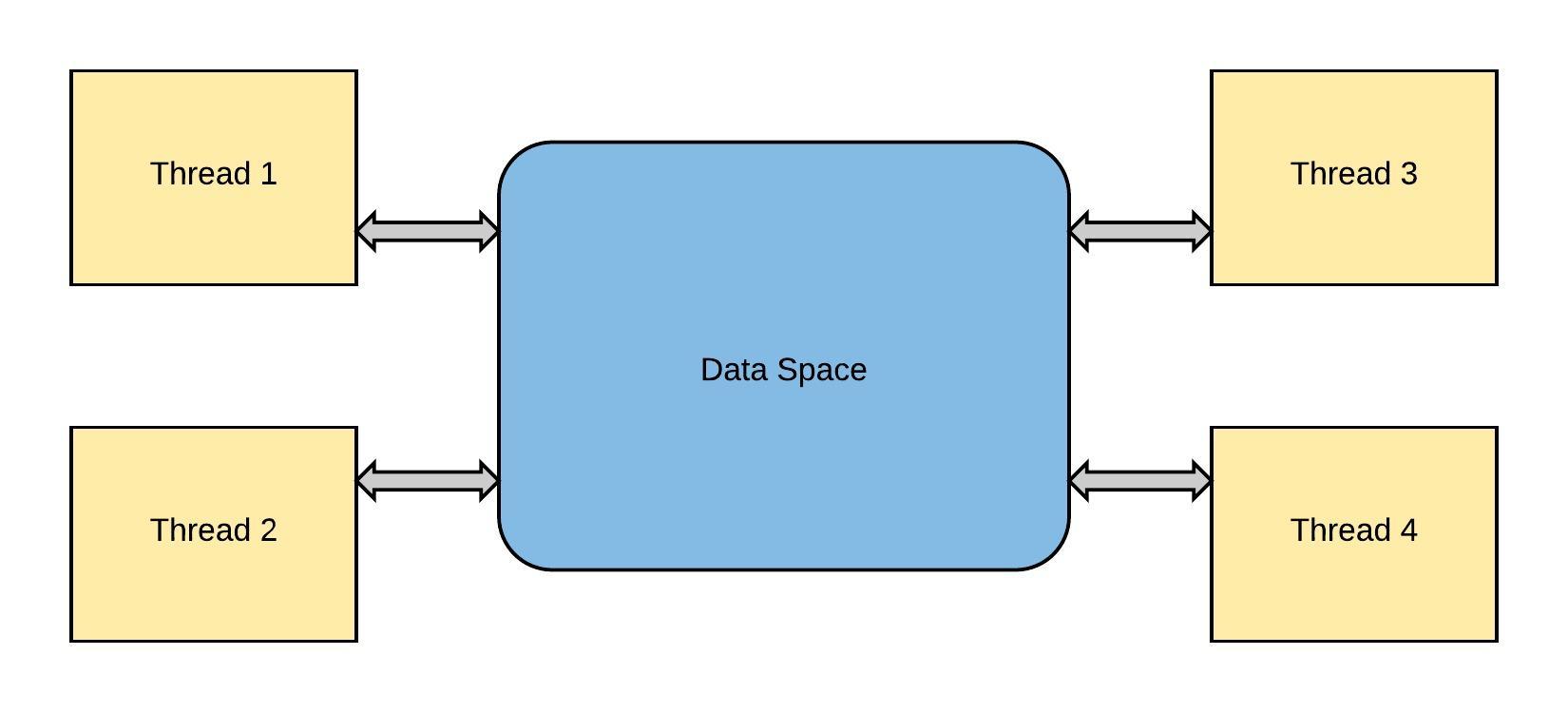
幸运的是,threading 模块是 Python 标准库的组成部分
import threading from queue import Queue import time
我们可以使用 threading 模块提供的 Thread 类来创建一个线程,Thread 类的初始化很简单,
可以使用 target 作为可调用对象,args 将参数传递给函数,并使用 start 启动线程
def testThread(num): print num if __name__ == '__main__': for i in range(5): t = threading.Thread(target=testThread, arg=(i,)) t.start()
如果你从未见过 __name__ =='__ main__' : 之前,它基本上是一种确保嵌套在其中的代码仅在脚本直接运行 ( 未导入 ) 时运行的方法
锁
你可能经常希望你的线程能够使用或修改线程之间通用的变量,为此,你必须使用一个称之为 「 锁 」 lock 的东西。每当函数想要修改变量时,它就会锁定该变量。当另一个函数想要使用变量时,它必须等到该变量被解锁
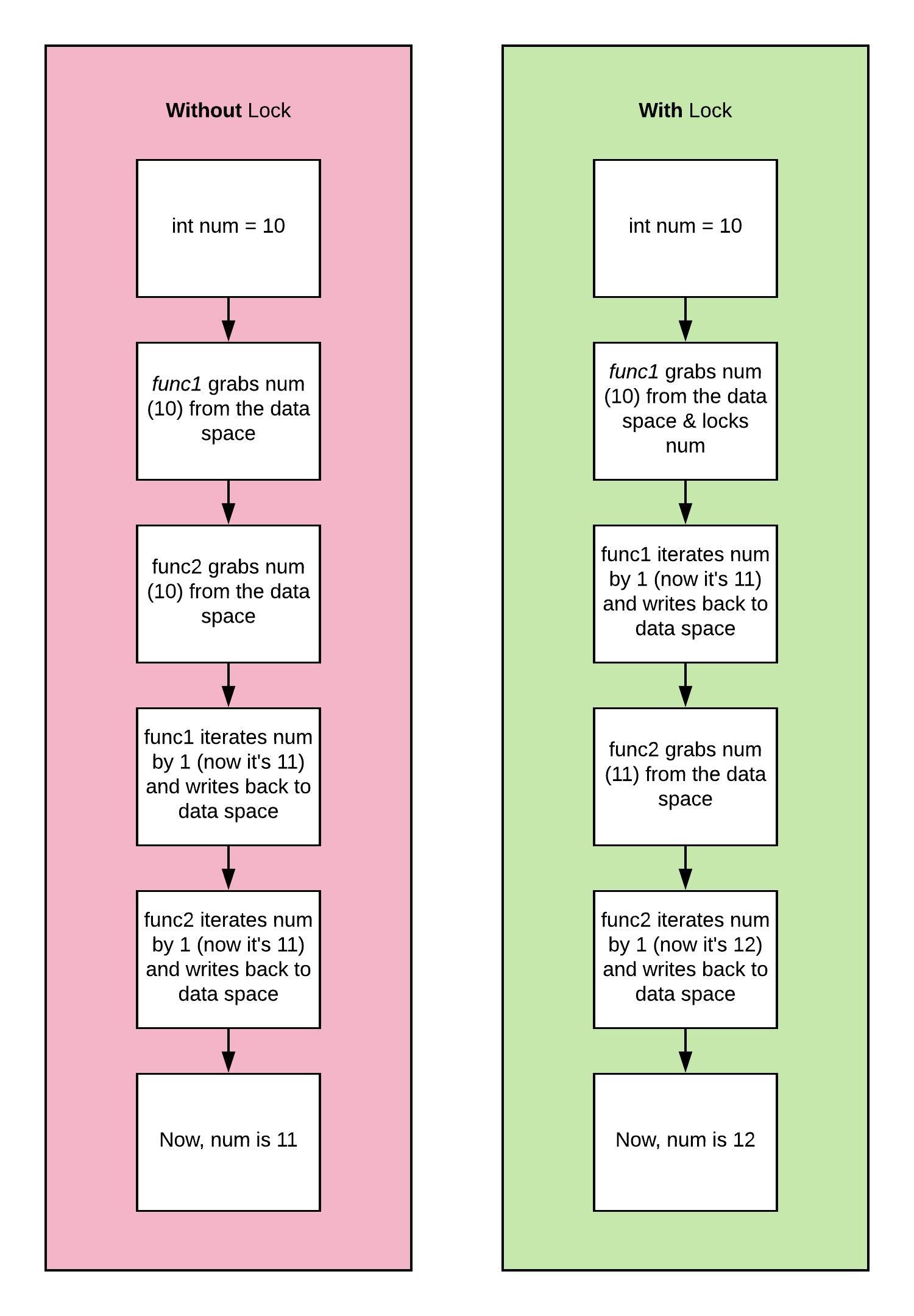
想象一下两个函数都将变量迭代 1。锁 ( lock ) 允许你确保一个函数可以访问变量,执行计算,并在另一个函数可以访问同一个变量之前写回该变量
使用 threading 模块时,这也可能在你打印时发生,因为文本可能混乱 ( 并导致数据损坏 )
我们可以使用打印锁定以确保一次只能打印一个线程
print_lock = threading.Lock() def threadTest(): # when this exits, the print_lock is released with print_lock: print(worker) def threader(): while True: # get the job from the front of the queue threadTest(q.get()) q.task_done() q = Queue() for x in range(5): thread = threading.Thread(target = threader) # this ensures the thread will die when the main thread dies # can set t.daemon to False if you want it to keep running t.daemon = True t.start() for job in range(10): q.put(job)
这里,我们有 10 个想要完成的任务,5 个工作进程将处理这些任务
多线程并不总是完美的解决方案
我发现许多文章倾向于忽略使用他们刚刚试图教你的工具的负面影响。使用所有这些工具时最重要的是要了解有利有弊
例如
- 管理线程会产生开销,因此不希望将其用于基本任务 ( 如示例 )
- 增加程序的复杂性,这会使调试更加困难
什么是多处理?它与线程有什么不同?
如果没有多进程,由于 GIL ( Global Interpreter Lock ,全局解释器锁 ) ,Python 程序无法最大化系统的使用。Python 在设计时并没有考虑到个人计算机可能有多个核心 ( 显示出了该语言有多古老 ),因此 GIL 是必需的,因为 Python 不是线程安全的,并且在访问 Python 对象时存在全局强制锁定。虽然不完美,但它是一种非常有效的内存管理机制
我们可以做些什么 ?
多进程 multiprocessing 允许我们创建可以并发运行的程序 ( 绕过 GIL ) 并使用所有的 CPU 核心。虽然它与 threading 线程库有根本的不同,但语法非常相似
multiprocessing 库为每个进程提供了自己的 Python 解释器,每个进程都有自己的 GIL
因此,与线程相关的常见问题 ( 例如数据损坏和死锁 ) 不再是问题。由于进程不共享内存,因此无法同时修改相同的内存
下面是一段使用多进程的代码
```python import multiprocessing def spawn(): print('test!')
if name == 'main': for i in range(5): p = multiprocessing.Process(target=spawn) p.start()
如果你使用了共享的数据库,则需要确保在开始新进程之前等待相关进程完成 ```python for i in range(5): p = multiprocessing.Process(target=spawn) p.start() p.join() # this line allows you to wait for processes
如果要将参数传递给进程,可以使用 args 执行此操作
import multiprocessing def spawn(num): print(num) if __name__ == '__main__': for i in range(25): ## right here p = multiprocessing.Process(target=spawn, args=(i,)) p.start()
这是一个简洁的例子,因为正如你所注意到的那样,数字并没有按照你想要的顺序输出 ( 没有使用 p.join() )
与线程一样,多处理仍然存在缺陷......你必须自己选择使用哪种毒药
- 来自进程之间的数据混乱的
I/O开销 - 整个内存被复制到每个子进程中,这对于更重要的程序来说可能是很多开销
我应该怎么选择
- 如果您的代码有大量的
I/O或网络使用情况 - 多线程是最好的选择,因为它的开销很低 - 如果你有一个 GUI 程序 - 多线程,因为你的 UI 线程不会被锁定
- 如果你的代码是 CPU 密集型的 - 应该使用多进程,前提是你的计算机有多个核心